파이썬으로 웹 크롤링을 하고 있다.
requests, BeautifulSoup 2개의 라이브러리를 통해서 구축을 하려고 한다.
requests 라이브러리 사용 방법
- 설치
pip install requests
- 소스
## parser.py
import requests
## HTTP GET Request
req = requests.get('http://www.naver.com')
## html 소스 처리
html = req.text
## HTTP Header값 확인
header = req.headers
## HTTP Status 값 확인 (200: 정상)
status = req.status_code
## HTTP처리 정상적 여부 (True/False)
is_ok = req.ok위의 처리로 하면 페이지 로딩을 확인 할 수 있다. 다만 html 형식이 str로 처리가 되어서 파싱을 하는데 어려움이 있다.
이 부분을 해결하기 위해 BeautifulSoup 라이브러리를 이용하려고 한다.
그중에서 bs4를 이용했다.
- 설치
pip install bs4- 소스
import requests
from bs4 import BeautifulSoup
# 페이지 호출
req = requests.get(site)
#데이터 담기
html = req.text
# html 파싱
soup = BeautifulSoup(html, 'html.parser')
#파싱 영역선택
site_menu = soup.select(
'div#kakaoWrap > div#kakaoContent> div#cSub > div > ul.list_issue'
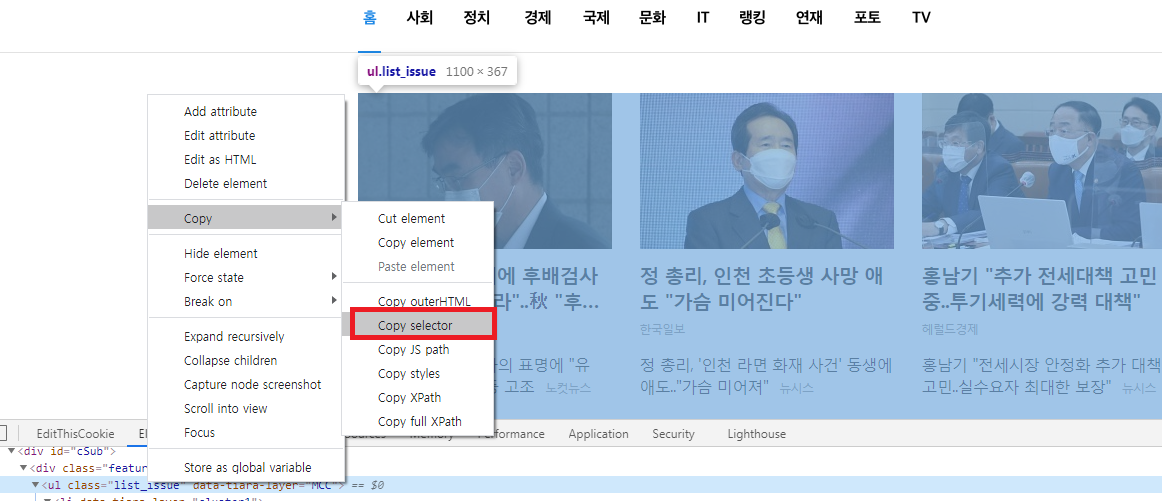
)soup.select를 모른다면 하단의 이미지를 통해서 위치를 파악할 수 있다.
다만 전체가 나오지 않으므로 상단 값 부터 찾아서 해준다.
라이브러리 페이지 : pypi.org/project/beautifulsoup4/
beautifulsoup4
Screen-scraping library
pypi.org
도큐먼트 사이트 : www.crummy.com/software/BeautifulSoup/bs4/doc/
Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation
Non-pretty printing If you just want a string, with no fancy formatting, you can call str() on a BeautifulSoup object (unicode() in Python 2), or on a Tag within it: str(soup) # ' I linked to example.com ' str(soup.a) # ' I linked to example.com ' The str(
www.crummy.com
다음 같은 경우는 한글이 안깨지고 있지만 특정 사이트에서 한글이 깨지는 경우가 있다.
그런 경우는 아래와 같이 호출 해야 가능하다.
import requests
from bs4 import BeautifulSoup
# 페이지 호출
req = requests.get(site)
# 파싱
soup = BeautifulSoup(req.content.decode('euc-kr', 'replace'), 'html.parser')
#파싱 영역
site_menu = soup.select(
'div > .cate'
)위의 소스 중 파싱 부분을 보면 decode를 통해서 한글 깨짐을 해결했다.
생각보다 편하고 간단하다.
'Dev > Python' 카테고리의 다른 글
| [python-library]py-hansepll 설치시 오류 (0) | 2020.12.07 |
|---|---|
| RuntimeError: The current Numpy installation (Feat.pandas-numpy) (0) | 2020.11.27 |
| Python-library [ wordninja ] / 단어분리(영어) (0) | 2020.09.17 |
| Python-library [ hyphenate] / 단어분리(영어) (0) | 2020.09.17 |
| Python-library[word2word]-단어번역 (0) | 2020.09.16 |